Learn about Amazon EMR (Elastic Map Reduce) – Cloud Big Data Platform from AWS
What is Amazon EMR ?
Amazon EMR is a Cloud big data Platform for large scale data processing , interactive SQL queries, ML (Machine Learning) applications using widely used Open-Source frameworks – Apache Spark, Presto, Hadoop, Hive, Trino, HBase & Flink
Amazon EMR Features
Following are some of the Features of Amazon EMR
- Ease of use
- Provision clusters in minutes: Launch an EMR cluster in minutes.
- Easily scale resources to meet business needs: Easily set scale out and scale in using EMR Managed Scaling policies
- EMR Studio: which is IDE for users to develop, visualize applications.
- EMR Managed Scaling: Automatically resizes your cluster for best performance at the lowest possible cost.
- EMR Managed Scaling: Automatically resizes your cluster for best performance at the lowest possible cost.
- Elasticity – Amazon EMR enables you to quickly and easily provision as much capacity as you need, and automatically or manually add and remove capacity.
- Cost Optimization
- Low Per-Second Pricing: Amazon EMR pricing is per-second with a one-minute minimum
- Amazon EC2 Spot Integration: Amazon EMR makes it easy to use Spot instances so you can save both time and money.
- Amazon S3 Integration: The EMR File System (EMRFS) allows EMR clusters to efficiently and securely use Amazon S3 as an object store for Hadoop.
- AWS Glue Data Catalog Integration: Use the AWS Glue Data Catalog as a managed metadata repository to store external table metadata for Apache Spark and Apache Hive.
- Flexible data stores – With Amazon EMR, you can leverage multiple data stores, including Amazon S3, the Hadoop Distributed File System (HDFS), and Amazon DynamoDB.
- Big Data Tools – Amazon EMR supports powerful and proven Hadoop tools such as Apache Spark, Apache Hive, Presto, and Apache HBase.
Benefits of Amazon EMR
There are many benefits in using Cloud Big Data Platform such as Amazon EMR over traditional on-prem Big data Platforms. Some Benefits are outlined below
- Differentiated performance for runtimes – Performance-optimized runtime for popular frameworks like Spark, Hive, Presto, and Flink
with 100% open-source API compatibility. - Best price-performance for big data analytics – Reduce cost using Amazon EC2 Spot, Amazon EMR managed scaling, and per-second billing
- Scalability and Flexibility – Provides ability to Scale your cluster up or down as per your computing needs.
- Deployment – Fully Managed Service which will perform installation, configuration , version upgrade, tuning automatically . This will reduce operational overhead.
- Decoupled Storage – Uses Amazon S3 as storage layer. Utilizing Amazon EMR for compute and Amazon S3 for Storage will provide decoupling architecture. This can help in data sharing across clusters.
- Improved availability and disaster recovery.
Amazon EMR Architecture
Following is the high level architecture of Amazon EMR. The central component of Amazon EMR is the cluster . A cluster is a collection of nodes on various AWS hosting options – Amazon EC2, Amazon EKS , AWS Outposts, Serverless.
Amazon EMR has three node types – Master, Core , Task nodes
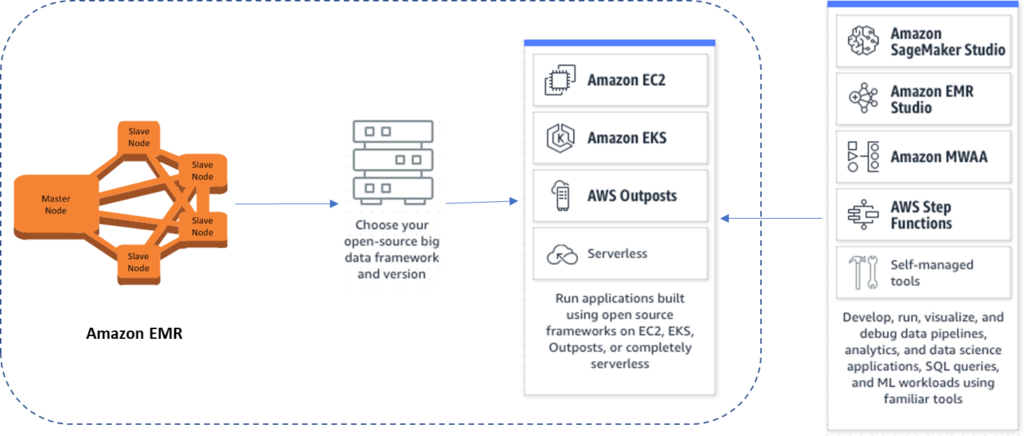
Following are the EMR Deployment Models
Amazon EMR on EC2
Amazon EMR on EC2 Process and analyze data for machine learning, scientific simulation, data mining, web indexing, log file analysis, and data warehousing. Amazon EMR on EC2 is recommended when you have need to utilize multiple frameworks ( like hive, presto, spark, hadoop).
Amazon EMR on EC2 has the following features
- Control over instances drives cluster-centric model
- Cannot run multiple versions of applications when dependencies collide
- Great for clusters running at high utilization
Following is high level architecture of Amazon EMR on EC2
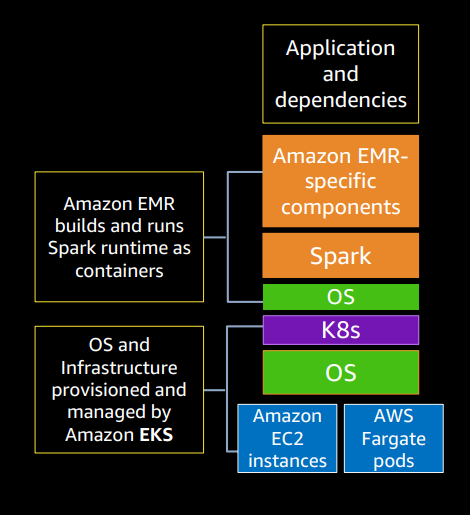
Amazon EMR on EKS
Amazon EMR on Amazon EKS enables you to submit Apache Spark jobs on demand on Amazon Elastic Kubernetes Service (EKS) without provisioning clusters.
With EMR on EKS, you can consolidate analytical workloads with your other Kubernetes-based applications on the same Amazon EKS cluster to improve resource utilization and simplify infrastructure management.
Amazon EMR on EKS has the following benefits
- Containerization drives job-centric model
- Run multiple versions of Spark per cluster / per job execution role
- Great for faster upgrade cycles
- Great for consolidating resources
- Support integration with Apache Airflow
- Native integration with Amazon S3, AWS Glue Data Catalog, and more
Following is high level architecture of Amazon EMR on EKS

Learn more about Amazon EMR on EKS , Refer the following AWS Presentation – https://d1.awsstatic.com/events/reinvent/2021/Amazon_EMR_on_EKS_ANT322.pdf
Amazon EMR on Outposts
AWS Outposts bring AWS services, infrastructure, and operating models to virtually any data center, co-location space, or on-premises facility. Amazon EMR is available on AWS Outposts, allowing you to set up, deploy, manage, and scale Apache Hadoop, Apache Hive, Apache Spark, and Presto clusters in your on-premises environments, just as you would in the cloud.
Amazon EMR on Outposts has the following benefits
- Augment on-premises processing capacity – Integrates with existing HDFS storage and provides scaling as per needs.
- Data Processing on-premises – For data that needs to be on-premises for governance, compliance , you can use EMR to deploy and run applications like Apache Hadoop and Apache Spark on-premises, close to your data.
- Accelerate data and workload migrations – Will provide the ability to test the EMR in real Production environment before making decision to migrate.
Amazon EMR Serverless
Amazon EMR Serverless is a serverless option in Amazon EMR that makes it easy for data analysts and engineers to run open-source big data analytics frameworks without configuring, managing, and scaling clusters or servers.
You will get all the features of EMR with out the need of managing the clusters. Amazon EMR serverless has the following benefits
- Simple to use – No servers to manage. Amazon EMR Serverless provisions, configures, and dynamically scales the compute and memory resources needed at each stage of your data processing application.
- Fast – Performance optimized runtime that is compatible with and over 2X faster than standard open source
- Cost effective – Pay only for the compute time and resources that you use.
- Comprehensive – Includes Amazon EMR Studio with Notebooks and familiar open source tools to easily develop, visualize, and debug applications
Following is high level architecture of EMR Serverless
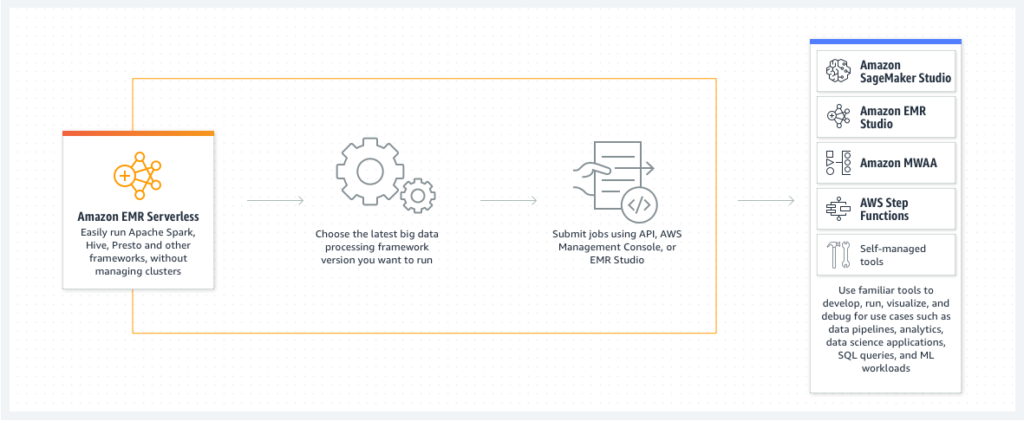
Learn more about Amazon EMR Serverless , Refer the following AWS Presentation – https://d1.awsstatic.com/events/reinvent/2021/New_Launch_Introducing_Amazon_EMR_Serverless_ANT218.pdf
Following are some of the widely utilized applications/frameworks in Amazon EMR ecosystem
EMR Hive
Hive is an open-source, data warehouse, and analytic package that runs on top of a Hadoop cluster. Hive use an SQL-like language called Hive QL which utilizes Tez jobs based on DAGs or Map reduce programs for execution.
For more information on EMR Hive on AWS, check out our post – http://www.cloudinfonow.com/aws-emr-hive/
EMR Hadoop
Hadoop is is an open-source Java software framework that supports massive data processing across a cluster of instances. It can run on a single instance or thousands of instances. Hadoop uses various processing models, such as MapReduce and Tez and uses a a distributed file system called HDFS to store data locally on the Cluster.
EMR Hadoop supports both Hadoop 2.x and Hadoop 3.x versions. HDFS storage is recommended as temporary data processing storage layer and utilize S3 as Persistent storage layer.
It is recommended to utilize EMR File system (EMRFS) for for reading and writing regular files from Amazon EMR directly to Amazon S3. EMRFS provides persistent data storage S3 layer for use with EMR Hadoop.
Following are basic components of the EMR Hadoop . Amazon EMR programmatically installs and configures applications in the Hadoop project, including Hadoop MapReduce, YARN, HDFS, and Apache Tez across the nodes in your cluster.
- Processing with Hadoop MapReduce, Tez, and YARN – Hadoop MapReduce and Tez, execution engines in the Hadoop ecosystem, process workloads using frameworks that break down jobs into smaller pieces of work that can be distributed across nodes in your Amazon EMR cluster.
- Storage using Amazon S3 and EMRFS – By using the EMR File System (EMRFS) on your Amazon EMR cluster, you can leverage Amazon S3 which is cost efficient as your data layer for Hadoop.
EMR Presto
Presto is a fast SQL query engine designed for interactive analytic queries over large datasets from multiple sources. Presto originated in Facebook and later open-sourced. Presto is a in-memory SQL engine for ad hoc analysis across multiple data sources.
Running Presto on Amazon EMR is a popular choice because Amazon EMR provides the latest, stable, open-source community Presto innovations and Amazon EMR platform-level optimizations for Presto workloads.
For more information on EMR Presto on AWS, check out our post – http://www.cloudinfonow.com/aws-presto-emr/
EMR Spark
Apache Spark is an open-source, distributed processing system used for big data workloads. It utilizes in-memory caching, and optimized query execution for fast analytic queries against data of any size.
EMR features Amazon EMR runtime for Apache Spark, a performance-optimized runtime environment for Apache Spark that is active by default on Amazon EMR clusters. Amazon EMR runtime for Apache Spark can be over 3x faster than clusters without the EMR runtime, and has 100% API compatibility with standard Apache Spark.
For more information on EMR Spark on AWS, check out our post – http://www.cloudinfonow.com/aws-emr-spark/
EMR Hudi
Apache Hudi is an open-source data management framework used to simplify incremental data processing and data pipeline development by providing record-level insert, update, upsert, and delete capabilities.
Hudi is supported in Amazon EMR and is automatically installed when you choose Spark, Hive, or Presto when deploying your EMR cluster. Data sets managed by Hudi are accessible not only from Spark (and PySpark) but also other engines such as Hive and Presto.
EMR Pricing Model
EMR Pricing depends on the type of EMR deployment model and usage of the EMR service . More details of EMR pricing are available on our post – http://www.cloudinfonow.com/aws-emr-pricing/
EMR New Features
AWS frequently adds new features. During AWS Reinvent , AWS released new features. More information available at https://mplay-assets.s3.amazonaws.com/sites/awsreinv21/_uploads/assets/bgezhexxjwmoevhk_awsreinv21.pdf
Pingback: AWS Hive • Cloud InfoNow
Pingback: AWS Presto • Cloud InfoNow
Pingback: AWS Spark • Cloud InfoNow