Overview of AWS Spark on Amazon EMR
What is Amazon EMR ?
Amazon EMR is a Cloud big data Platform for large scale data processing , interactive SQL queries, ML (Machine Learning) applications using widely used Open-Source frameworks – Apache Spark, Presto, Hadoop, Hive, Trino, HBase & Flink
To find out more information on Amazon EMR , check out our post – http://www.cloudinfonow.com/amazon-emr-eks-serverless/
What is Apache Spark ?
Apache Spark is an Open source distributed cluster computing framework . Following are some of the features of Spark
- Originated in 2009 at UC Berkley and gained mainstream usage since 2014.
- In-memory caching and optimized execution for fast performance (100x faster than Hadoop MapReduce)
Hadoop Execution Flow

Spark Execution Flow

- Designed for Batch Processing, Streaming Analytics, Machine Learning, Graph databases and adhoc queries.
- APIs for Java, Scala, Python, R and SQL.
Spark Ecosystem
Following are the key components of Spark EcoSystem
Spark Core: Spark Core is the underlying general execution engine for the Spark platform that all other functionality is built on top of.
Spark SQL : Spark SQL is a Spark module for structured data processing. It provides a programming abstraction called DataFrames and can also act as SQL query engine.
Spark Streaming: Spark Streaming enables powerful interactive and analytical applications across both streaming and historical data. Integrates with a wide variety of popular data sources, including HDFS, Flume, Kafka, and Twitter.
Machine Learning: MLlib is a scalable machine learning library that delivers both high-quality algorithms and blazing speed . The library is usable in Java, Scala, and Python as part of Spark applications.
GraphX: GraphX is a graph computation engine built on top of Spark that enables users to interactively build, transform and reason about graph structured data.
Spark Architecture
Following is high level architecture of Spark
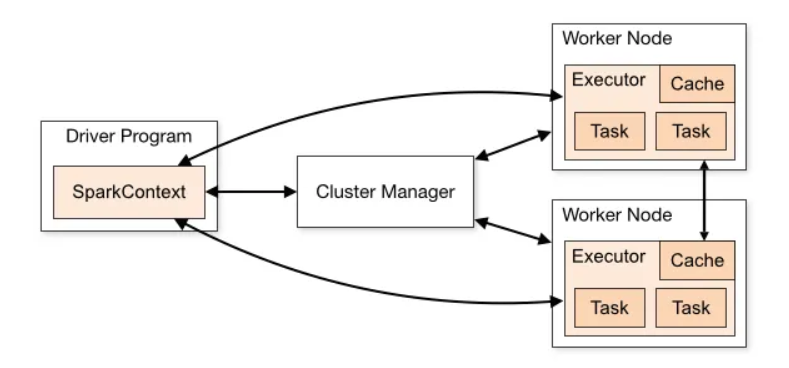
- Driver Program – The process running the main() function of the application and creating the SparkContext. It is also the program/job, written by the developers which is submitted to Spark for processing.
- Spark Context – Spark Context is the entry point to use Spark Core services and features.
- Cluster Manager – Spark uses cluster manager to acquire resources across the cluster for executing a job.. EMR Uses YARN as cluster manager.
- Worker Node – Worker Nodes are nodes which actually do data processing/heavy lifting on data.
- Executor – Executors are independent processes which run inside the Worker Nodes in their own JVMs. Data processing is actually done by these executor processes.
- Cache – Data stored in physical memory. Jobs can cache data so that it does not need to re-compute RDDs.
- Task – A task is a unit of work performed independently by the executor on one partition.
EMR Spark
Apache Spark is an open-source, distributed processing system used for big data workloads. It utilizes in-memory caching, and optimized query execution for fast analytic queries against data of any size.
EMR features Amazon EMR runtime for Apache Spark, a performance-optimized runtime environment for Apache Spark that is active by default on Amazon EMR clusters. Amazon EMR runtime for Apache Spark can be over 3x faster than clusters without the EMR runtime, and has 100% API compatibility with standard Apache Spark.
Following are some of the EMR Spark Runtime Features

Following is high level architecture of EMR Spark on EC2
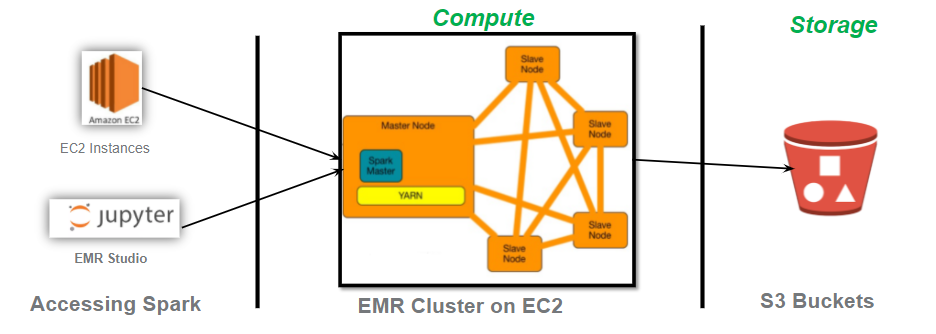
For more information on Accelerating Apache Spark with Amazon EMR, Pls check the Reinvent 2021 presentation at – https://d1.awsstatic.com/events/reinvent/2021/Deep_dive_Accelerating_Apache_Spark_with_Amazon_EMR_ANT401.pdf
Spark Tuning and Best Practices
Following are some of the Spark Tuning and Best practices
- Use dataset, dataframes instead of RDDs
- Implement partitioning and Bucketing for large tables.
- Avoid groupbykey on large datasets .Use reduceByKey instead.
- Use Broadcast join when joining a larger table with smaller table to avoid shuffling of data across nodes.
- Use coalesce to repartition in decrease number of partitions
- Use caching when reusing the same file multiple times
- Explicitly cast the types in the queries.
- Avoid collect() on large Dataframes.
- Filter or reduce the Dataframes before joining
- Use columnar formats like Parquet to scan less data
- Recommend to have tables bucketed by same key when joining multiple large tables to avoid shuffling.
- If joining large tables, Increase the number of shuffle partitions (spark.sql.shuffle.partitions) .
- Limit the number of partitions while invoking bucketing on tables.
- Watch out for Skewed data.
EMR Spark Pricing
Spark is one of the framework on Amazon EMR service. Hence, EMR Spark Pricing depends on type of EMR deployment and usage of EMR clusters. More details of EMR pricing are available on our post – http://www.cloudinfonow.com/aws-emr-pricing/
Pingback: Amazon EMR • Cloud InfoNow