Use AWS Glue for Databricks
Databricks Deployment has a central Hive Metastore by Default for Data Catalog. There will be option to utilize External Hive Metastore Instance or AWS Glue Catalog.
This post will walkthrough the steps to Integrate AWS Glue Catalog as the Metastore for Databricks Runtime
Step 1 : In AWS Console
Create an instance profile to access a Glue Data Catalog. Attach the below Policy
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "GrantCatalogAccessToGlue",
"Effect": "Allow",
"Action": [
"glue:BatchCreatePartition",
"glue:BatchDeletePartition",
"glue:BatchGetPartition",
"glue:CreateDatabase",
"glue:CreateTable",
"glue:CreateUserDefinedFunction",
"glue:DeleteDatabase",
"glue:DeletePartition",
"glue:DeleteTable",
"glue:DeleteUserDefinedFunction",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetPartition",
"glue:GetPartitions",
"glue:GetTable",
"glue:GetTables",
"glue:GetUserDefinedFunction",
"glue:GetUserDefinedFunctions",
"glue:UpdateDatabase",
"glue:UpdatePartition",
"glue:UpdateTable",
"glue:UpdateUserDefinedFunction"
],
"Resource": [
"*"
]
}
]
}
Step 2 : In AWS Console
Modify the Instance profile created for Databricks EC2 access . This is to allow Databricks to pass the instance profile you created in Step 1 to the EC2 instances for the Spark clusters.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1403287045000",
"Effect": "Allow",
"Action": [
"ec2:AssociateDhcpOptions",
"ec2:AssociateIamInstanceProfile",
"ec2:AssociateRouteTable",
"ec2:AttachInternetGateway",
"ec2:AttachVolume",
"ec2:AuthorizeSecurityGroupEgress",
"ec2:AuthorizeSecurityGroupIngress",
"ec2:CancelSpotInstanceRequests",
"ec2:CreateDhcpOptions",
"ec2:CreateInternetGateway",
"ec2:CreatePlacementGroup",
"ec2:CreateRoute",
"ec2:CreateSecurityGroup",
"ec2:CreateSubnet",
"ec2:CreateTags",
"ec2:CreateVolume",
"ec2:CreateVpc",
"ec2:CreateVpcPeeringConnection",
"ec2:DeleteInternetGateway",
"ec2:DeletePlacementGroup",
"ec2:DeleteRoute",
"ec2:DeleteRouteTable",
"ec2:DeleteSecurityGroup",
"ec2:DeleteSubnet",
"ec2:DeleteTags",
"ec2:DeleteVolume",
"ec2:DeleteVpc",
"ec2:DescribeAvailabilityZones",
"ec2:DescribeIamInstanceProfileAssociations",
"ec2:DescribeInstanceStatus",
"ec2:DescribeInstances",
"ec2:DescribePlacementGroups",
"ec2:DescribePrefixLists",
"ec2:DescribeReservedInstancesOfferings",
"ec2:DescribeRouteTables",
"ec2:DescribeSecurityGroups",
"ec2:DescribeSpotInstanceRequests",
"ec2:DescribeSpotPriceHistory",
"ec2:DescribeSubnets",
"ec2:DescribeVolumes",
"ec2:DescribeVpcs",
"ec2:DetachInternetGateway",
"ec2:DisassociateIamInstanceProfile",
"ec2:ModifyVpcAttribute",
"ec2:ReplaceIamInstanceProfileAssociation",
"ec2:RequestSpotInstances",
"ec2:RevokeSecurityGroupEgress",
"ec2:RevokeSecurityGroupIngress",
"ec2:RunInstances",
"ec2:TerminateInstances"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-glue-access>"
}
]
}
Replace the arn in the above “PassRole” with your Databricks IAM role.
Step 3 : In Databricks Workspace
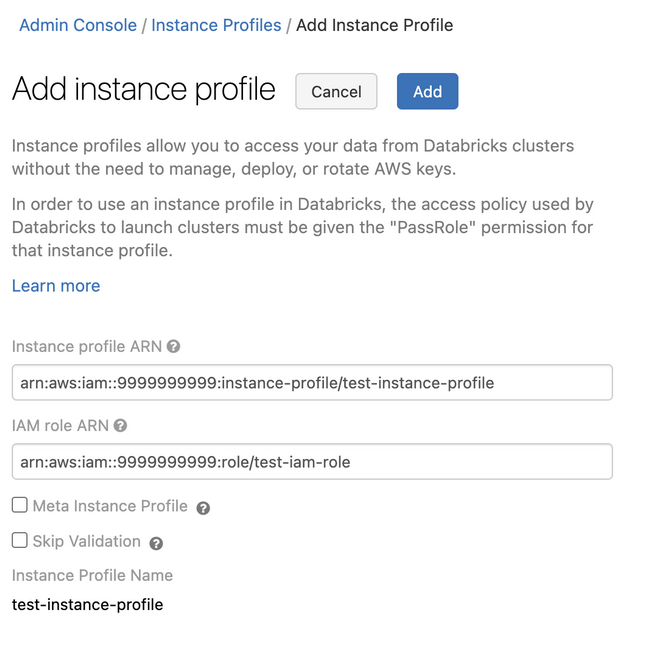
Add the Glue Catalog instance profile to a Databricks workspace
- Go to the admin console.
- Click the Instance Profiles tab.
- Click the Add Instance Profile button. A dialog displays.
- Paste in the Instance Profile ARN from Step 1.
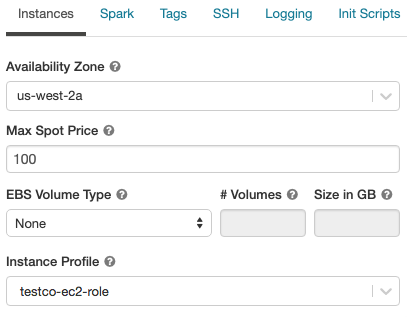
Step 4: In Databricks Workspace
- Create a cluster.
- Click the Instances tab on the cluster creation page.
- In the Instance Profiles drop-down list, select the instance profile.
- Verify that you can access the Glue Catalog, using the following command in a notebook
show databases; If the command succeeds, this Databricks Runtime cluster is configured to use Glue.
References
https://docs.databricks.com/data/metastores/aws-glue-metastore.html